In dem Beitrag über Docker Monitoring wurde gezeigt, wie man Statistiken aus Docker bekommt und diese visualisiert am Beispiel der Hauptspeicher Benutzung. Die Filesystem Benutzung funktioniert analog und eine Datei zum Import in Grafana liegt auch im Github Repository.
https://github.com/StMoelter/blog-docker-monitoring/blob/master/cAdvisor-1480198253658.json
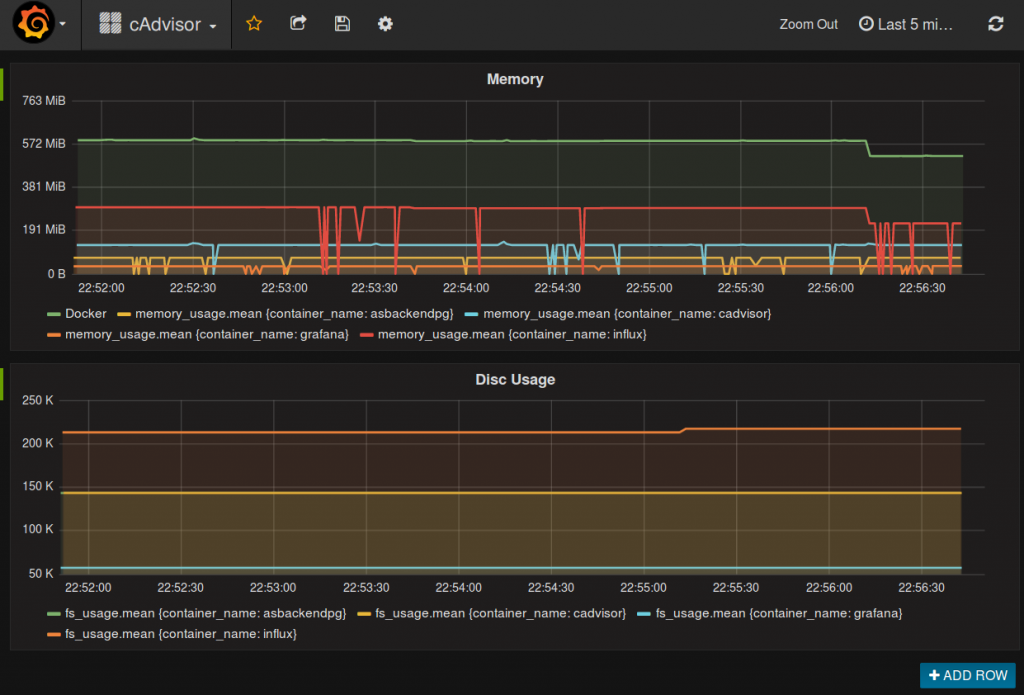
Möchte man analog dazu eine Übersicht über die CPU Auslastung, ergiebt sich fogendes Bild:
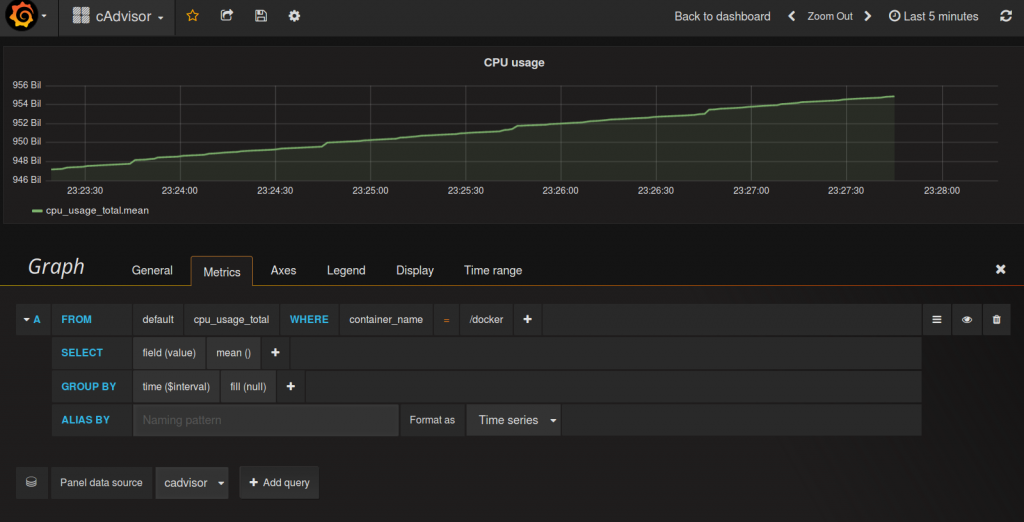
Bei dem Query sieht man, dass dies analog zum Speicherverbrauch aufgebaut wurde. container_name=“/docker“ gibt uns wohl den kompletten Speicherverbrauch des Dockersystems zurück. Der Graph steigt allerdings, gewünscht hätten wir uns eher eine Ausgabe in Prozent gewünscht. Auch die Werte an der Y-Achse sehen etwas merkwürdig und hoch aus.
Grund dafür ist, dass cpu_usage_total (wie auch die anderen cpu_usage_ Werte) diese kumulativ ausgeben. Sprich die gesamte CPU Zeit in Nanosekunden wird angezeigt. Um den Wert zwischen 2 Messpunkten zu erhalten müssen also diese Punkte voneinander subtrahiert und durch die verstrichene Zeit dividiert werden.
Grafana baut nun Datenbankstatements, welche die daten gruppieren. Der ‚Last‘ oder ‚Max‘ Selector der Influxdb sollte den richtigen Wert zurück geben.
Im Setup in dem ober erwähnten Blog Eintrag ist die Influxdb unter:
http://localhost:8083/
erreichbar. Oben rechts ist als Datenbank ‚cadvisor‘ einzustellen.
Nun kann man die Statements testen. Als erstes wird geschaut, ob LAST und MAX wirklich die gleichen Daten zurück geben. Das Statement dazu:
SELECT LAST("value"), MAX("value") FROM "cpu_usage_total" WHERE "container_name" = '/docker' AND time > now() - 15m GROUP BY time(30s) fill(null)
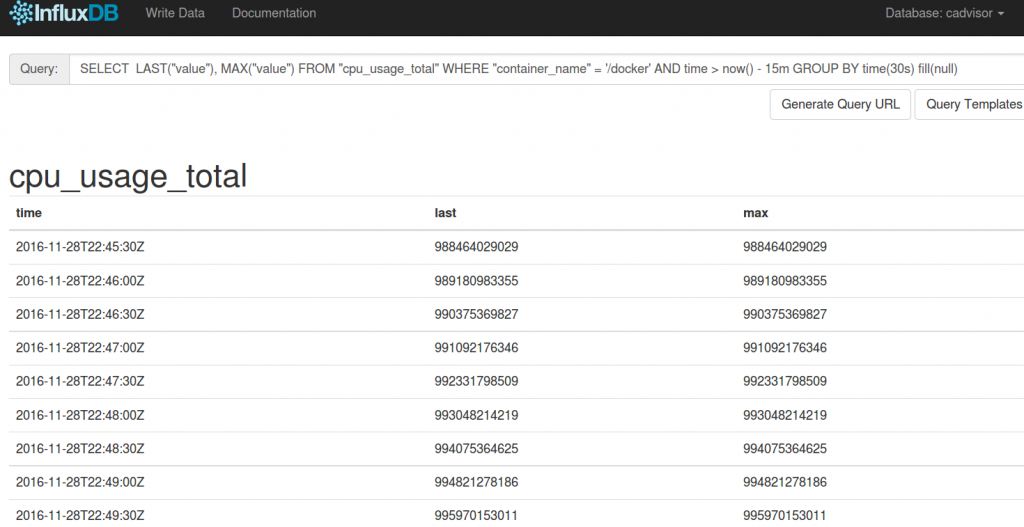
Wie man sieht, beide Werte sehen gleich aus. Wir gehen also weiter mit ‚LAST‘ ohne dafür eine genauere Begründung zu haben.
Die Influxdb kennte einen DIFFERENCE Operator, schauen wir uns diesen auch mal an:
SELECT DIFFERENCE(LAST("value")), LAST("value") FROM "cpu_usage_total" WHERE "container_name" = '/docker' AND time > now() - 15m GROUP BY time(30s) fill(null)
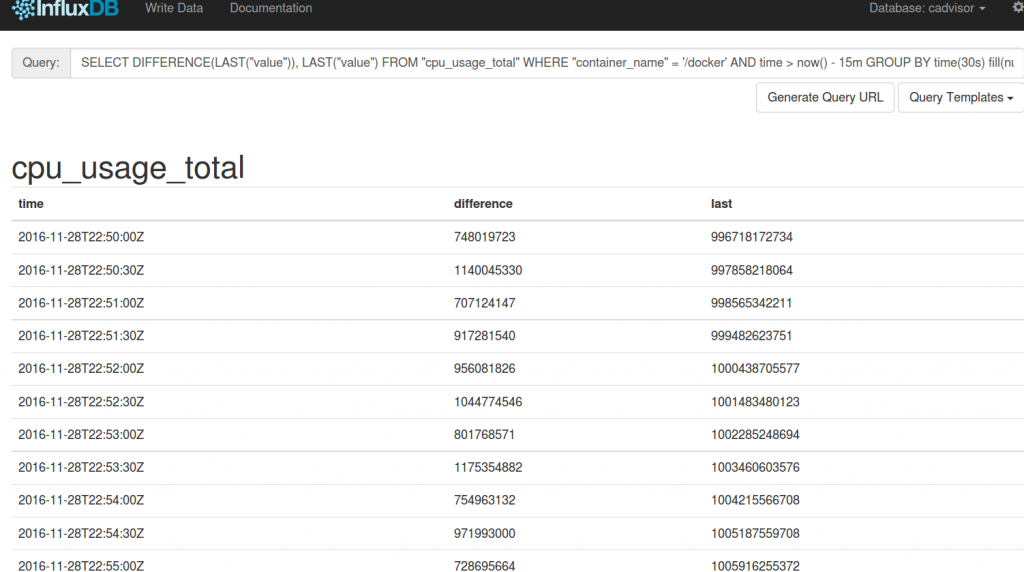
Das sieht auch gut aus, obwohl uns die Angabe in Nanosekunden auch nicht sonderlich weiter bringt. Also benutzen wir die Influxdb Funktion ELAPSED, um an die Zeit zwischen den Messpunkten zu gelangen:
SELECT DIFFERENCE(LAST("value")), LAST("value"), ELAPSED(LAST("value")) FROM "cpu_usage_total" WHERE "container_name" = '/docker' AND time > now() - 15m GROUP BY time(30s) fill(null)
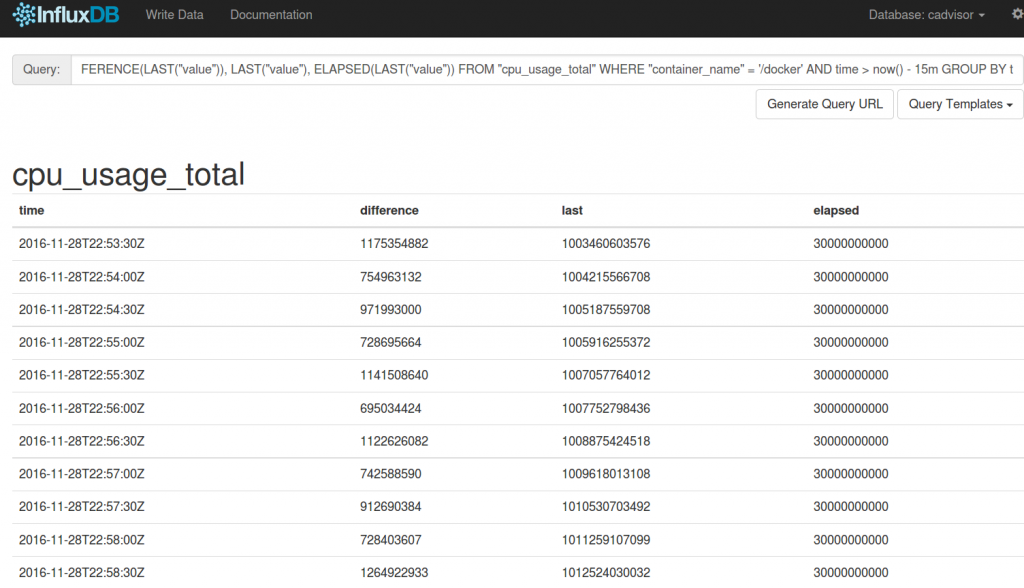
unter der Spalte ‚elapsed‘ erhalten wir nun auch den Wert der verstrichenen Nanosekunden zurück.
Nun kann man dividieren:
SELECT DIFFERENCE(LAST("value")) / ELAPSED(LAST("value")) FROM "cpu_usage_total" WHERE "container_name" = '/docker' AND time > now() - 15m GROUP BY time(30s) fill(null)
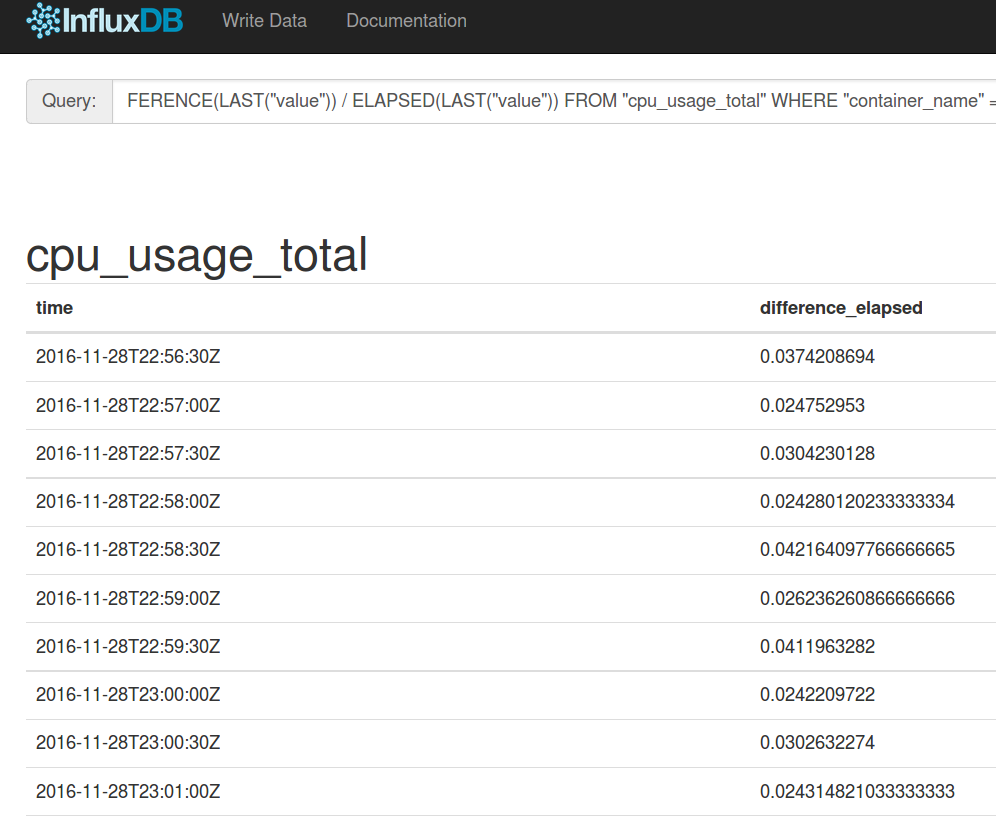
Das können wir nun in Grafana einbauen. Dazu klicket man auf das kleine Menu-Icon rechts neben dem Statement in dem Grafana-Screen von oben. Dann wählt man ‚Toggle Edit Mode‘, bis man eine Zeile zum editieren hat. In diese kommt:
SELECT DIFFERENCE(LAST("value")) / ELAPSED(LAST("value")) FROM "cpu_usage_total" WHERE "container_name" = '/docker' AND $timeFilter GROUP BY time($interval) fill(null)
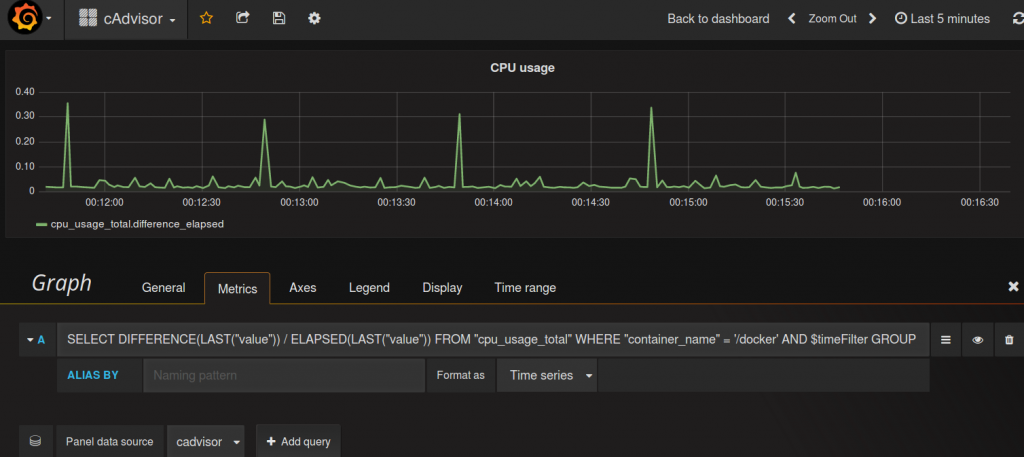
Die Einteilung in der Dezimalform finde ich vollkommen OK und lasse sie so. Vielleicht wären auch Prozente schön, wie man möchte.
Die Übersicht ist schon hilfreich, allerdings wäre es auch gut die CPU Benutzung pro Container zu sehen.
Dazu wird ein weiteres Query hinzugefügt, durch Klick auf ‚Add Query‘. Es erscheint ein weiteres Feld für ein Query, dort kann man das erste über Copy and Paste duplizieren.
Als erstes löscht man den Teil in der Where-Clause, welches den Container auswählt und fügt den Container Namen zur Gruppierung hinzu:
SELECT DIFFERENCE(LAST("value")) / ELAPSED(LAST("value")) FROM "cpu_usage_total" WHERE $timeFilter GROUP BY container_name, time($interval)
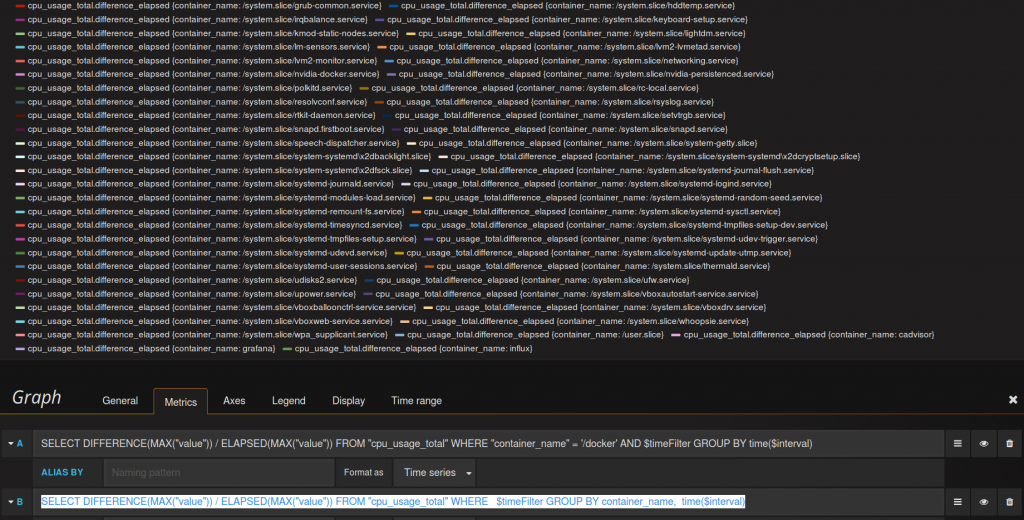
Der cAdvisor liefert sehr viele ‚Container-Namen‘ aus, das scheinen interne Messwerte zu sein, die hier erstmal nicht von Belang sind. Diese sollen nicht angezeigt werden.
Die unwichtigen Container starten alle mit einem ‚/‘, diese können über eine Regex aussortiert werden:
SELECT DIFFERENCE(LAST("value")) / ELAPSED(LAST("value")) FROM "cpu_usage_total" WHERE "container_name" !~ /\// AND $timeFilter GROUP BY container_name, time($interval)
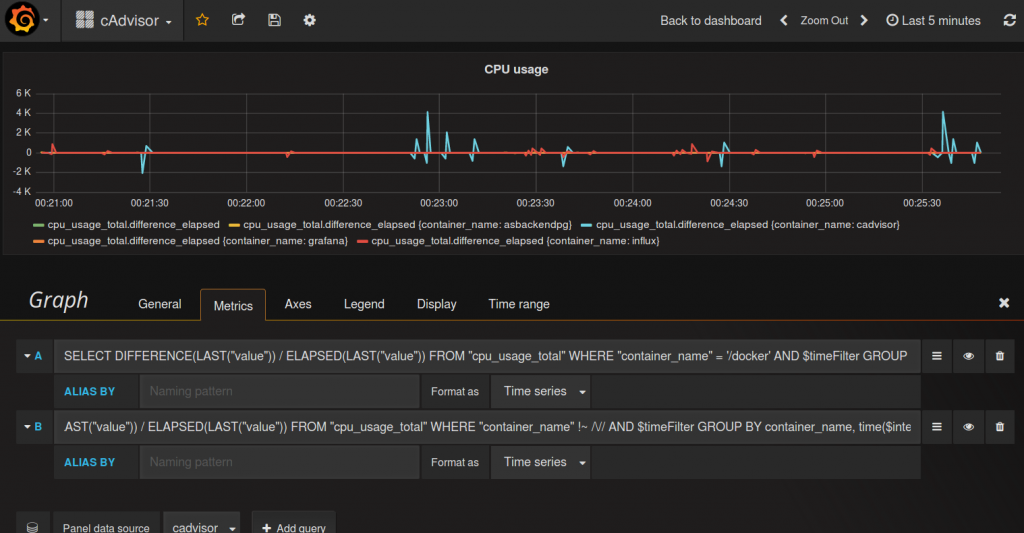
Sieht besser aus aber die Artefakte mit den hohen und negativen Zahlen sollen noch Weg.
Dies zeigt sich als nicht trivial, bei ersten Tests ist aufgefallen, dass ein MAX in der Query stabiler ist als LAST, deshalb wird mit MAX weitergearbeitet.
Um zu sehen, wo diese her kommen schaut man sich das Query, welches von Grafana an die influxdb geschickt wird genau an. Das kann man mit:
docker log -f influx
auf der Konsole sehen. Man findet etwas wie
SELECT+DIFFERENCE%28MAX%28%22value%22%29%29+%2F+ELAPSED%28MAX%28%22value%22%29%29+ FROM+%22cpu_usage_total%22+ WHERE++%22container_name%22+%21~+%2F%5C%2F%2F+AND++time+%3E+1480760303s+and+time+%3C+1480760903s+ GROUP+BY+container_name%2C++time%28200ms%29
für das Query und stellt fest, dass im die Gruppierung nach der Zeit in Intervallen von 200ms erfolgt. Die sind sehr eng und wenn es keine Messwerte in einem Intervall gibt, also 0 zurückgeliefert wird, so kann das die Artefakte erzeugen.
Als Lösung soll die Zeit der Gruppierung erhöht werden, so dass immer ein Datenpunkt gefunden wird. Nach etwas ausprobieren zeigt sich 5 Sekunden als ein guter und stabiler Wert.
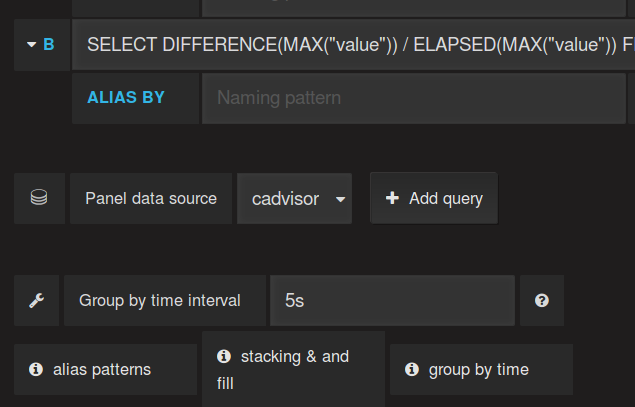
‚Group By time interval‘ ist hier die Einstellung der Wahl.
Man sehe den Graphen jetzt:
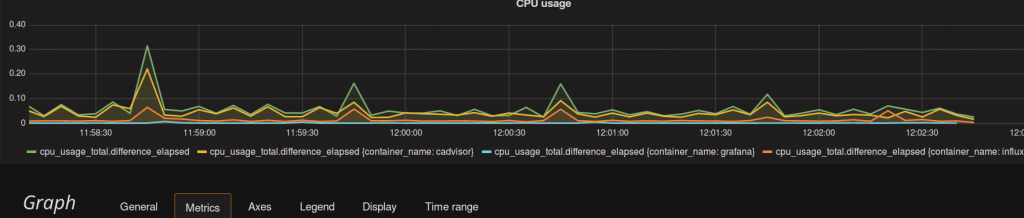
Das sieht soweit ganz gut aus.
Soweit so gut, aber ein kleiner Test, ob der Graph auch das tut was er soll, wäre cool.
Dazu wird etwas Last in einem Container erzeugt
docker run --rm --name stress -it progrium/stress --cpu 8 --timeout 60s
Hier wird ein Container mit dem Namen ’stress‘ erzeugt und der setzt 60 Sekunden lang die ganzen 8 Kerne in meinem Rechner unter Volllast.

Prinzipiell funktioniert die Anzeige, allerdings ist die Genauigkeit nicht so wie eigentlich gewünscht.
Wie auch immer kann man prinzipiell den Resourcenverbrauch der CPU mit diesem Graph einschätzen, so dass er erstmal – zumindest für meine Zwecke – seinen Dienst tut.