Das Thema KI gewinnt immer mehr an Bedeutung, so wie die Presse schreibt geht Google schon von ‚mobile first‘ zu ‚AI first‘. Von daher macht es Sinn sich mit diesem Thema zu beschäftigen. Als Quelle für einen tieferen Einblick dienen mir die freien Kurse bei Udacity. Sich die Theorie anzueignen ist eine recht trockene Angelegenheit, von daher brauche ich auch praktische Anwendungen, welche ich umsetzen kann.
Eine ganz coole Anwendung sind natürlich da Chatbots. Die meiste Interaktion über das Internet findet z. Zt. mit dem Smartphone statt. Fast jedes hat einen Chat-Anwendung schon implementiert, die meisten Anwender benutzen zur Kommunikation auch diese Chats.
Von daher kann eine Anwendung, die als Chatbot daher kommt eine niederschwellige Benutzung bringen. Anstatt eine App zu installieren, welche noch nach Berechtigungen fragt, kann ein Bot einfacher benutzt werden.
Die großen Player wie Google, Facebook, Amazon, IBM usw. stellen schon fertige Lösungen dazu zur Verfügung. Bei den fertigen Lösungen handelt es sich um Software die natürlich auf den Servern der Anbieter läuft. Da automatisiertes Lernen von der Menge der eingegebenen Daten abhängt, macht es natürlich Sinn diese Plattformen zu öffnen, um die so erhaltenen Daten zur Optimierung des eigenen Produktes zu nutzen.
Als Beispiel einer dieser Plattformen habe ich mir mit api.ai das Produkt von Google angeschaut. Wobei das Produkt nicht vom Google selber Entwickelt, sondern eingekauft wurde.
Man möchte aber nicht unbedingt die Daten der User und seine eigene Daten von dritter Stelle bearbeitet und begutachtet haben. Von daher macht das Projekt rasa_nlu einen guten Eindruck. Es handelt sich hier um freie Software, welche den Bereich des NLP (= natural language processing) also der Verarbeitung von eingegebenen Freitext in eine strukturierte Form (json) tätigt. Dabei kann rasa_nlu auch mit der deutschen Sprache (lt. Dokumentation) umgehen.
Die freie Software ist nicht so komfortable, wie das Portal. Abgesehen von den Integrationen in bestehende Chats / Messenger, welche api.ai mitbringt scheinen die zusätzlichen Features auf api.ai allerdings von dem benötigtem Backend auch übernommen werden zu können. Wie zu erwarten kann man sich mit rasa_nlu über einen erhöhten Aufwand die Hoheit über seine Daten / Nutzerdaten erhalten.
TL;DR: Habe einige Zeit verwendet um rasa_nlu zum laufen zu bringen, mit einem schlechten Ergebnis, auf dem man keinen vernünftigen Service / Bot bauen kann. Bin aber weiter am Thema dran, weitere Beitrag mit api.ai folgt.
rasa nlu
Die Software ist auf github veröffentlicht und kommt auch schon mit einer Docker-Integration und einem Image auf dem Docker-Hub daher, ausprobiert habe ich die Version 0.4.2. Die Version im Docker-Hub hat noch einen kleinen Bug beim Spacy Trainer, der im aktuellen master Branch gefixed ist. Von daher habe ich vom heutigen master, in dem das Problem gefixed wurde ein Docker-Image online gestellt.
Um den NLP Prozessor zum Laufen zu bringen müssen folgende Schritte getätigt werden:
- Datenpersistierung des Docker-Containers
- Konfiguration des Backends
- Download von SpaCy Daten für die deutsche Sprache
- Training anhand von Testdaten durchführen
- Konfiguration anpassen
- Starten des Servers mit den Trainierten Daten (Modell)
Datenpersistierung
Dazu bindet man am Besten Verzeichnisses des Hosts an den Docker-Container. Das geht recht enfach mit einem docker-compose.yml File. Meines sieht in etwa so aus:
version: ‚2‘
services:
rasa_nlu:
image: stmoelter/rasa_nlu:0.5.1
ports:
– „5000:5000“
container_name: rasa_nlu
command: ’start –config=/config/config_spacy_de.json‘
volumes:
– ~/workspace/tests/rasa_nlu_data/config:/config
– ~/workspace/tests/rasa_nlu_data/models:/models
– ~/workspace/tests/rasa_nlu_data/data/mitie:/app/data
– ~/workspace/tests/rasa_nlu_data/data/spacy:/usr/local/lib/python2.7/site-packages/spacy/data
Wobei die Verzeichnissse des Hosts natürlich den örtlichen Gegebenheiten anzupassen sind.
Konfiguration des Backends
Man kann 2 Backends konfigurieren, ‚Mitie‘ nur für Englisch, also fällt die Wahl auf das SpaCy-Backend mit der deutschen Sprache.
Details über die Konfigartionsdatei findet sich hier:
http://rasa-nlu.readthedocs.io/en/latest/config.html
In dem oben definierten config Verzeichnisses des Hosts habe ich eine config_spacy_de.json mit dem Inhalt:
{
"backend": "spacy_sklearn",,
"language": "de",
"path" : "/models"
}
erstellt. Dabei ist zu beachten, dass der Docker Prozess als User root läuft und die Verzeichnisse / Dateien auf dem Host sinnigerweise als root und eigener User lesbar und schreibbar sind.
Download von SpaCy Daten für die deutsche Sprache
Dazu ruft man den Container mit dem ‚download spacy de‘ Kommando auf:
docker run download spacy de
Bei mir auf dem Rechner sind das dann ~1,6GByte Daten, welche im data Verzeichnis (s. o.) erstellt werden.
Training anhand von Testdaten durchführen
Dazu braucht man erst einmal Testdaten für die deutsche Sprache. Das Lernen kann via REST Interface (POST /train) des Servers erledigt werden. Bein ersten Versuch hatte ich damit schlechte Ergebnisse erhalten, von daher nehmen wir lieber den ’normalen‘ Weg, wie im Tutorial der Dokumentation beschrieben. Dadurch kann man zu Debug-Zwecken das Visualisierungstool benutzen.
Test-Daten
Basierend auf den Testdaten im Repo, habe ich eine eigene Test Datei mit deutschen Phrasen erstellt. Dabei soll eine Zeitabfrage, sowie eine Suche bei Wikipedia getriggert werden können. Die Aufgaben müssen natürlich von einem zu erstellendem Backend geleistet werden.
rasa_nlu erzeugt von Dem Text ein ‚Intent‘ und evtl dazugehörige ‚Entities‘. Ein ‚Intent‘ ist z.B. ‚greet‘, wenn der User ‚Hallo‘ oder ähnlich eingibt. Eine Abfrage bei der Wikipedia benötigt einen ‚Intent‘, also ‚global_search‘ als Suche bei Wikipedia. Dazu benötigt man natürlich ein Suchwort, was die Entität (global_word) darstellt.
Es gibt für die englische Sprache einen Tets-Datei:
https://github.com/golastmile/rasa_nlu/blob/master/data/examples/rasa/demo-rasa.json
Darauf basierend habe ich eine deutsche Datei erstellt:
{
"rasa_nlu_data": {
"entity_examples": [
{
"text": "Hallo",
"intent": "greet",
"entities": []
},
{
"text": "Hi",
"intent": "greet",
"entities": []
},
{
"text": "Wie geht es Dir",
"intent": "greet",
"entities": []
},
{
"text": "Guten Tag",
"intent": "greet",
"entities": []
},
{
"text": "Alles klar",
"intent": "greet",
"entities": []
},
{
"text": "Wie spät ist es",
"intent": "time",
"entities": []
},
{
"text": "Welche Uhrzeit haben wir",
"intent": "time",
"entities": []
},
{
"text": "Kennst Du Kram",
"intent": "global_search",
"entities": [
{
"start": 10,
"end": 14,
"value": "Kram",
"entity": "global_word"
}
]
},
{
"text": "Was ist Kram",
"intent": "global_search",
"entities": [
{
"start": 8,
"end": 12,
"value": "Kram",
"entity": "global_word"
}
]
},
{
"text": "Ja",
"intent": "affirm",
"entities": []
},
{
"text": "Jau",
"intent": "affirm",
"entities": []
},
{
"text": "Sicher",
"intent": "affirm",
"entities": []
},
{
"text": "Klaro",
"intent": "affirm",
"entities": []
},
{
"text": "Aber Hallo",
"intent": "affirm",
"entities": []
},
{
"text": "Immer",
"intent": "affirm",
"entities": []
},
{
"text": "bye",
"intent": "goodbye",
"entities": []
},
{
"text": "tschüß",
"intent": "goodbye",
"entities": []
},
{
"text": "tschüss",
"intent": "goodbye",
"entities": []
},
{
"text": "tschö",
"intent": "goodbye",
"entities": []
},
{
"text": "stop",
"intent": "goodbye",
"entities": []
},
{
"text": "ende",
"intent": "goodbye",
"entities": []
},
{
"text": "ok",
"intent": "affirm",
"entities": []
},
{
"text": "fantastisch",
"intent": "affirm",
"entities": []
},
{
"text": "mehr",
"intent": "more",
"entities": []
},
{
"text": "weiter",
"intent": "more",
"entities": []
}
],
"intent_examples": [
{
"text": "Aber Hallo",
"intent": "greet"
},
{
"text": "Alles klar",
"intent": "greet"
},
{
"text": "Guten Tag",
"intent": "greet"
},
{
"text": "Hallo",
"intent": "greet"
},
{
"text": "Hi",
"intent": "greet"
},
{
"text": "Immer",
"intent": "affirm"
},
{
"text": "Ja",
"intent": "affirm"
},
{
"text": "Jau",
"intent": "affirm"
},
{
"text": "Kennst Du Kram",
"intent": "global_search"
},
{
"text": "Klaro",
"intent": "affirm"
},
{
"text": "Sicher",
"intent": "affirm"
},
{
"text": "Was ist Kram",
"intent": "global_search"
},
{
"text": "Welche Uhrzeit haben wir",
"intent": "time"
},
{
"text": "Wie geht es Dir",
"intent": "greet"
},
{
"text": "Wie spät ist es",
"intent": "time"
},
{
"text": "bye",
"intent": "goodbye"
},
{
"text": "ende",
"intent": "goodbye"
},
{
"text": "fantastisch",
"intent": "affirm"
},
{
"text": "mehr",
"intent": "more"
},
{
"text": "ok",
"intent": "affirm"
},
{
"text": "stop",
"intent": "goodbye"
},
{
"text": "tschö",
"intent": "goodbye"
},
{
"text": "tschüß",
"intent": "goodbye"
},
{
"text": "tschüss",
"intent": "goodbye"
},
{
"text": "weiter",
"intent": "more"
}
]
}
}
Die Daten wurden in der Datei rasa_de.json in das config Verzeichnis gelegt.
Diese Datei wird in der config Datei config_de_spacy.json refernziert über den Eintrag:
"data": "/config/rasa_de.json"
Um festzustellen, ob die Daten valide sind und es keine Tipp / Syntaxfehler gibt, kommt rasa_nlu mit einem kleinen Datenvisualisierer daher. Leider hat Stert-Script im Docker-Container dafür keine Option. Aber mit dem Befehl:
docker-compose run --entrypoint 'python -m rsa_nlu.visualize /config/rasa_de.json' -p 8080:8080 rasa_nlu
kann man den Entrypoint überschreiben und die Visualisierung starten. Mit dem Brower kann man dann auf dem Port 8080 (https://localhost:8080) die Daten checken.
Für das Training gibt es das gleiche Problem mit dem Docker Start-Script. Alternativ kann man das Training auch über die API antriggern:
http://rasa-nlu.readthedocs.io/en/latest/http.html
Leider gibt es beim Aufruf über http Probleme mit den Umlauten, so dass sinvoller erscheint, den Weg über das File zu gehen, zumal via http Interface auch die Datenvisualisierung nicht verfügbar ist.
Der Aufruf zum Training überschreibt auch wieder den Entrypoint:
docker-compose run --entrypoint 'python -m rasa_nlu.train -c /config/config_spacy_de.json' rasa_nlu
Bei mir wirft das Training leider immer die Warnung:
/usr/local/lib/python2.7/site-packages/sklearn/metrics/classification.py:1113: UndefinedMetricWarning: F-score is ill-defined and being set to 0.0 in labels with no predicted samples.
Aber es wird ein Modell erstellt.
Konfiguration anpassen
Nach dem Training erscheint im model Verzeichnis ein Verzeichnis mit den gelernten Daten. Diese müssen dem Server für die ‚Prediction‘, also Verarbeitung der Sprache, bekannt gemacht werden.
Die geschieht auch über die config_spacy_de.json Datei:
"server_model_dir": "/models/model_20170121-113333"
Wobei der Pfad zum model Verzeichnis natürlich an den aktuellen anzupassen ist.
Starten des Servers mit den Trainierten Daten (Modell)
docker-compose up
Startet den Server. Auf die option -d verzichte ich hier erstmal, um die Log-Dateien sehen zu können.
Testen und erste Prediction
Wie in der http API dokumentiert ist startet man die Verarbeitung (Prediction) über einen POST-Request. Um diese abzusetzen benutze ich gerne die Chrome-Erweiterung Postman.
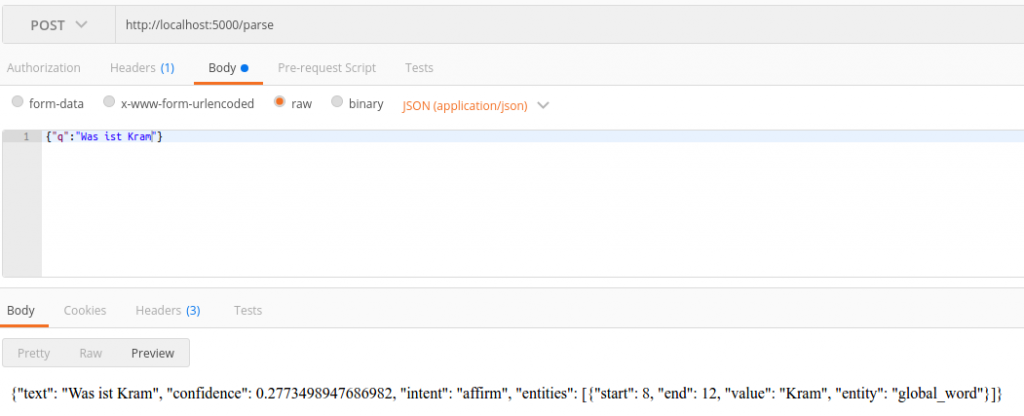
OK, das klappt also nicht. Intent ist falsch und die ‚Confidence‘ ist mit ~0.28 schlechter als erwartet.
Hab das mit verschiedenen Test-Daten für die deutsche Sprache probiert. Diese auch mit api.ai erstellt und dann importieren lassen, um die Menge der Daten zu erhöhen.
Alles mit wenig Erfolg und der gleichen Warnung beim Training. Werde da noch hinterher schauen. Aber die weiteren Tests mach ich erstmal auf api.ai.
Mehr in einem weiteren Blog Beitrag.